自动主从切换
下面我们来模拟主库故障,需要将从库提升为主库的场景。
模拟主库故障
使用kill命令,将主库进程杀死。例如:
$ kill -9 18049
主库故障后,从库系统日志中会出现错误:
FATAL: could not connect to the primary server: could not connect to server: Connection refused
Is the server running on host "node1" (192.168.56.101) and accepting
TCP/IP connections on port 1921?
从库提示无法连接到主库。
从库提升
使用pg_ctl promote命令来提升从库。
pg_ctl promote
LOG: received promote request
LOG: redo done at 0/6000110
LOG: selected new timeline ID: 2
LOG: archive recovery complete
LOG: database system is ready to accept connections
done
server promoted
一旦pg_ctl promote命令正确完成,此时从库即备提升为主库,可以正常对外提供服务。
当原主库故障后,通常这些故障并不会导致数据丢失,例如:宕机、机器重启故障。如果原主库故障解决之后,通常我们全把原主库转换成新主库的Standby备库。正常一般是需要重新搭建备库,因为原主库的一些数据还没有同步过去就把备库激活了,备库相当于丢失了一些数据。从而重新搭建备库的话,如果数据库很大,基础备份执行时间会很长,解决这个问题的方法可以使用pg_rewind命令。不需要复制太多的数据就可以把原主库转换成新主库的备库。
使用pg_rewind命令要求原主库必须把wal_log_hints参数设置成on,这样配置的主库在出现故障时才能使pg_rewind命令。
如果没有把参数wal_log_hints设置成on,运行pg_rewind时会报错:
[halo@node1 halo]$ pg_rewind -D $PGDATA --source-server='host=10.16.16.165 user=pgrewind password=123456 dbname=halo0root' -P
pg_rewind: connected to server
pg_rewind: fatal: target server needs to use either data checksums or "wal_log_hints = on"
下面演示pg_rewind的使用方法。
主库:node1 备库:node2
当node1故障了,现将node2升级为主库。
[halo@node2 ~]$ pg_ctl promote
server promoted
之后把node1启动,然后执行pg_rewind命令:
[halo@node1 ~]$ pg_rewind -D $PGDATA --source-server='host=node2 user=pgrewind password=123456 dbname=halo0root' -P
pg_rewind: fatal: target server must be shut down cleanly
报错需要把node1启动后,再正常关闭。
[halo@node1]$ pg_ctl start
done
server started
[halo@node1]$ pg_ctl stop
done
server stopped
然后再执行pg_rewind:
[halo@node1]$ pg_rewind -D $PGDATA --source-server='host=node2 user=pgrewind password=123456 dbname=halo0root' -P
pg_rewind: connected to server
pg_rewind: servers diverged at WAL location 0/30000D8 on timeline 1
pg_rewind: rewinding from last common checkpoint at 0/3000060 on timeline 1
pg_rewind: reading source file list
pg_rewind: reading target file list
pg_rewind: reading WAL in target
pg_rewind: need to copy 51 MB (total source directory size is 72 MB)
52873/52873 kB (100%) copied
pg_rewind: creating backup label and updating control file
pg_rewind: syncing target data directory
pg_rewind: Done!
注意,上面的“-D”参数指向本地的目录,“node2”可以是IP地址,user需要是超级用户。
pg_rewind执行完成之后,需要手动创建文件“standby.signal”:
touch $PGDATA/standby.signal
并将postgresql.auto.conf文件中的信息删掉。然后配置postgresql.conf中添加如下内容:
primary_conninfo = 'user=replica password=123456 channel_binding=prefer host=node2 port=1921 sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=halo target_session_attrs=any'
这样原主库node1才能变成新主库node2的备库。
现在启动node1数据库,就变成了node2的备库:
[halo@node1]$ pg_ctl start
waiting for server to start....2022-04-21 15:08:08.127 CST [23501] LOG: starting Halo 14.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.3.1 20190507 (NFS Server 8.3.1-5), 64-bit
2022-04-21 15:08:08.127 CST [23501] LOG: listening on IPv4 address "0.0.0.0", port 1921
2022-04-21 15:08:08.127 CST [23501] LOG: listening on IPv6 address "::", port 1921
2022-04-21 15:08:08.127 CST [23501] LOG: listening on Unix socket "/var/run/halo/.s.PGSQL.1921"
2022-04-21 15:08:08.129 CST [23502] LOG: database system was interrupted while in recovery at log time 2022-04-21 15:05:24 CST
2022-04-21 15:08:08.129 CST [23502] HINT: If this has occurred more than once some data might be corrupted and you might need to choose an earlier recovery target.
2022-04-21 15:08:08.160 CST [23502] LOG: entering standby mode
2022-04-21 15:08:08.161 CST [23502] LOG: redo starts at 0/30000D8
2022-04-21 15:08:08.162 CST [23502] LOG: invalid record length at 0/30190E8: wanted 24, got 0
2022-04-21 15:08:08.166 CST [23505] LOG: started streaming WAL from primary at 0/3000000 on timeline 2
2022-04-21 15:08:08.167 CST [23502] LOG: consistent recovery state reached at 0/3019120
2022-04-21 15:08:08.167 CST [23501] LOG: database system is ready to accept read only connections
done
server started
注意:一定要先建好standby.signal文件,再启动数据库。
11.6 自动主从切换
Halo数据库的2 节点的主从自动切换是基于keepalived实现的。keepalived是Linux下一个轻量级别的高可用解决方案。
在该示例中,我们基于keepalived实现2节点的主从自动切换。
准备
-
主从已完成搭设,并正常运行。
-
keepalived组件已安装。
-
VIP已完成规划。
-
SElinux已禁用。
配置
将<Halo安装目录($HALO_HOME)>/etc下的health_check.sh.sample和keepalived.conf.sample拷贝至/etc/keepalived目录下并重命名为health_check.sh和keepalived.conf。
编辑keepalived.conf,主要的修改点为:
…
script "/etc/keepalived/health_check.sh <Halo安装路径($HALO_HOME)> <数据库群集路径($PGDATA)> <VIP>
…
interface <网卡名称,如enp1s0>
…
virtual_ipaddress {
<VIP>
}
…
中从两边都需要进行配置。配置完成后,启动keepalived。先启动主的keepalived,再启动从的keepalived:
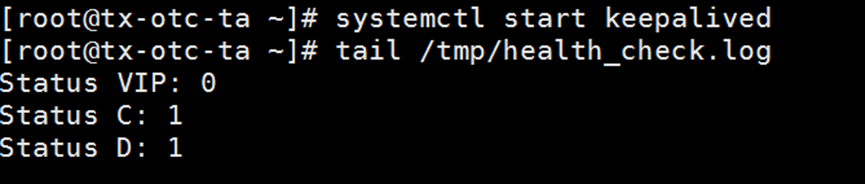
systemctl start keepalived
确保keepalived正常运行。
我们规划192.168.1.82,192.168.1.83作为主从的IP,192.168.1.84作为虚拟IP(VIP)。切换完成后需要将原主库恢复成备库,并重新启动keepalived。
1.主从切换switchover
确定流复制的状态和keepalive的状态
192.168.1.82的keepalive正常运行,192.168.1.84绑定在192.168.1.82服务器的网卡ens18上
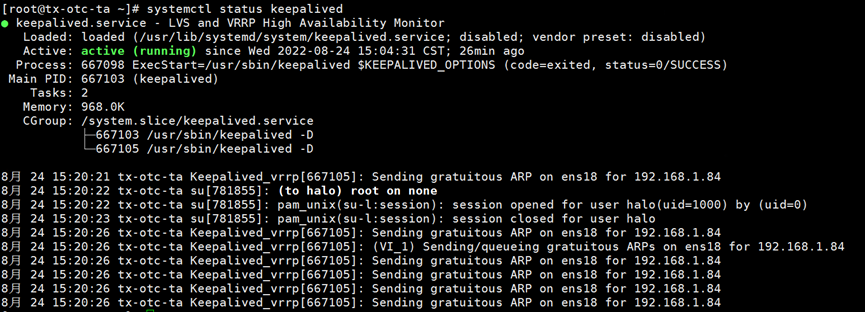
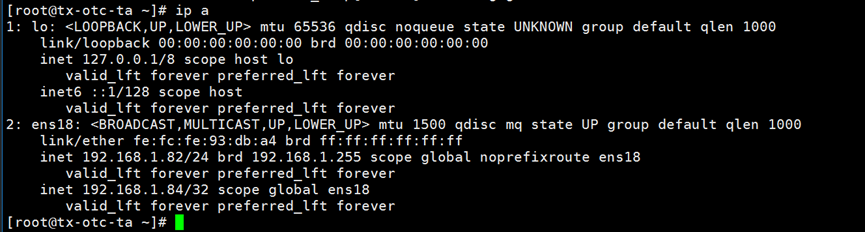
192.168.1.83上的keepalive正常运行。网卡ens18只有一个IP192.168.1.83
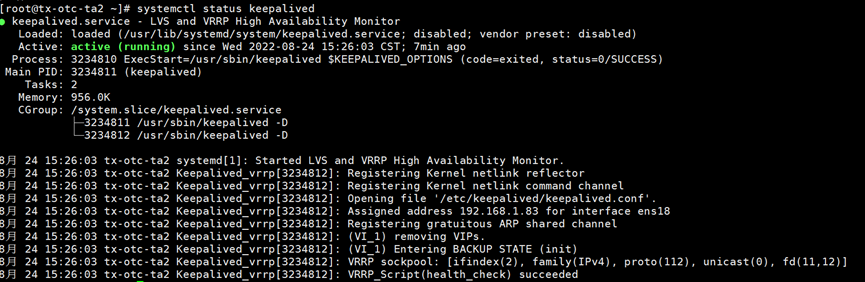
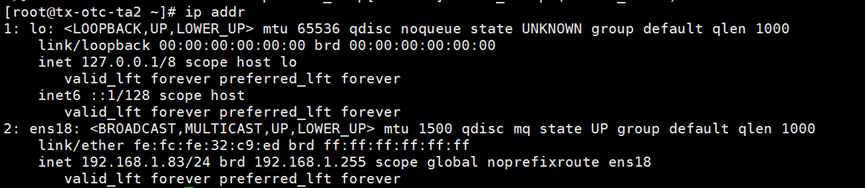
主库192.168.1.82正常关闭halo数据库

192.168.1.84 VIP马上漂移到192.168.1.83服务器,192.168.1.83成为新主库
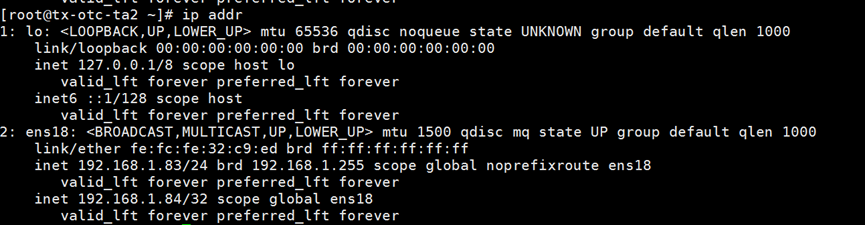
192.168.1.82原主库恢复为备库
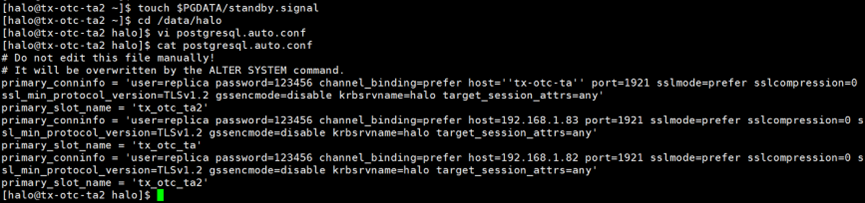
在数据目录中创建standby.signal文件。确定postgresql.auto.conf文件的��参数primary_conninfo参数中的host是否设置正确。
touch $PGDATA/standby.signal

确定postgresql.auto.conf中的primary_slot_name是否创建。如果没有创建需要使用函数pg_create_physical_replication_slot在新主库(192.168.1.83)创建slot
select * from pg_replication_slots;
select pg_create_physical_replication_slot('tx_otc_ta');

主库Halo实例会一直保留预写日志(WAL)文件,直到所有备库所需的复制插槽都确认已接收到特定段为止。
打开数据库之后,主从流复制就已经建好了

在新主库(192.168.1.83)上确认流复制已经建立。
select * from pg_stat_replication;

在新备库192.168.1.82启动keepalive服务,这样两节点的自动主从复制就恢复了原来的状态。
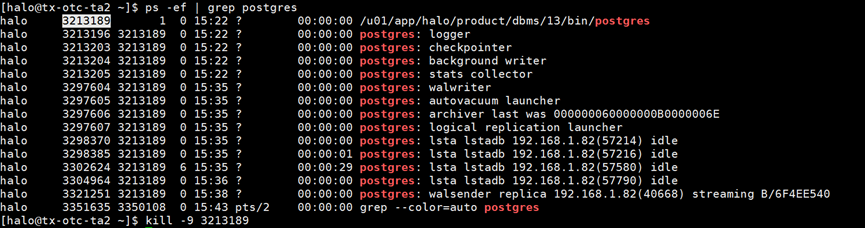
2.故障转移failover
模拟数据库进程突然中止。在192.168.1.83使用kill -9杀掉halo的主进程
192.168.1.84 VIP漂移到192.168.1.82服务器上
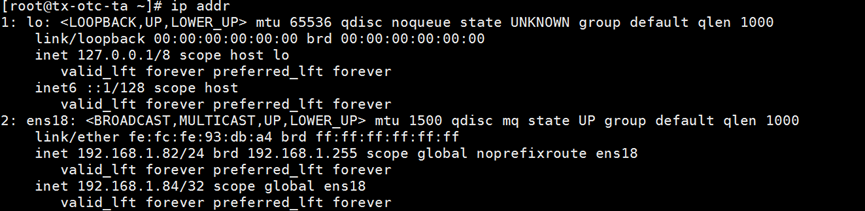
192.168.1.83原主库恢复为备库
failover的情况下原主库恢复为备库的方法有较多钟,需要视情况而定。
第一种是和switchover一样,先touch standby.signal文件,然后确定postgresql.auto.conf文件的设置,和复制槽的创建与否。
第二种是使用pg_basebackup重建从库,命令如下:
pg_basebackup -F p -X stream -v -P -h 192.168.1.82 -p 1921 -U replica -D $PGDATA -R -C --slot tx_otc_ta2
第三种是使用pg_rewind命令。pg_rewind不需要从源目录拷贝所有的数据文��件,而是会对比时间线发生偏离的点,只拷贝变化过的文件,这样对于数据量很大的情况下速度更快。
命令如下:
pg_rewind -D $PGDATA --source-server='host=192.168.1.82 user=halo password=halo dbname=halo0root' -P
确定192.168.1.82上有复制槽。
select * from pg_replication_slots;

打开192.168.1.83数据库,恢复流复制。

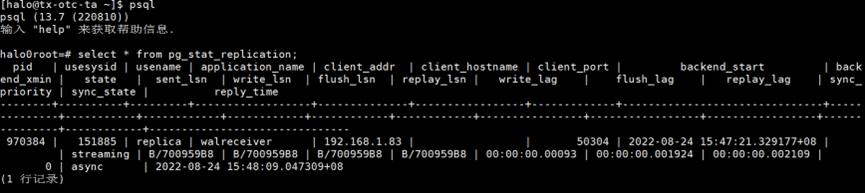
192.168.1.82上查看流复制的状态。
select * from pg_stat_replication;
192.168.1.83上启动keepalived,恢复自动主从切换
